Diego Ongaro 与 John Ousterhout
斯坦福大学
本技术报告为 [32] 的扩展版;页边灰色条标注为新增内容。发表于 2014 年 5 月 20 日。
Raft 是一种用于管理复制日志的共识算法。其效果与(多)Paxos 等价,效率相当,但结构不同;这使得 Raft 比 Paxos 更易理解,并为构建实用系统提供了更好的基础。为提高可理解性,Raft 将共识的关键要素分离,如 leader 选举、日志复制与安全性,并强化一致性以减少需要考虑的状态数量。用户研究表明,学生更容易学会 Raft 而非 Paxos。Raft 还包含一种新的集群成员变更机制,通过重叠多数来保证安全。
共识算法使一组机器能够作为可承受部分成员故障的协调整体工作,因此在构建可靠的大规模软件系统中扮演关键角色。过去十年间,Paxos [15, 16] 主导了共识算法的讨论:多数共识实现基于或受其影响,Paxos 也成为教授共识的主要载体。
遗憾的是,尽管有大量使其更易理解的尝试,Paxos 仍然非常难懂。此外,其架构需要复杂改动才能支持实用系统。因此,无论是系统构建者还是学生都在与 Paxos 角力。
在自身与 Paxos 角力之后,我们着手寻找一种新的共识算法,为系统构建和教育提供更好基础。我们的做法不同寻常:首要目标是可理解性——能否为实用系统定义一种共识算法,并以明显比 Paxos 更易学的方式描述?此外,我们希望算法能帮助形成系统构建者所必需的直觉。算法不仅要正确,而且要让人一眼看出为何正确。
这项工作的结果是一种名为 Raft 的共识算法。在设计 Raft 时,我们采用了提高可理解性的具体技术,包括分解(Raft 将 leader 选举、日志复制与安全性分开)和状态空间缩减(相对 Paxos,Raft 减少了非确定性程度以及各服务器日志不一致的方式)。对两所大学 43 名学生的用户研究表明,Raft 明显更易理解:在学完两种算法后,其中 33 名学生在回答 Raft 相关问题上优于 Paxos。
Raft 与现有共识算法(尤其是 Oki 与 Liskov 的 Viewstamped Replication [29, 22])在许多方面相似,但具有若干新特点:
我们相信 Raft 在教育与实现基础上均优于 Paxos 及其他共识算法:更简单、更易理解;描述足够完整以满足实用系统需求;有多个开源实现并被多家公司使用;安全性已形式化规范并证明;效率与其他算法相当。
本文其余部分介绍复制状态机问题(第 2 节)、讨论 Paxos 的优缺点(第 3 节)、描述我们关于可理解性的一般思路(第 4 节)、给出 Raft 共识算法(第 5–8 节)、评估 Raft(第 9 节)并讨论相关工作(第 10 节)。
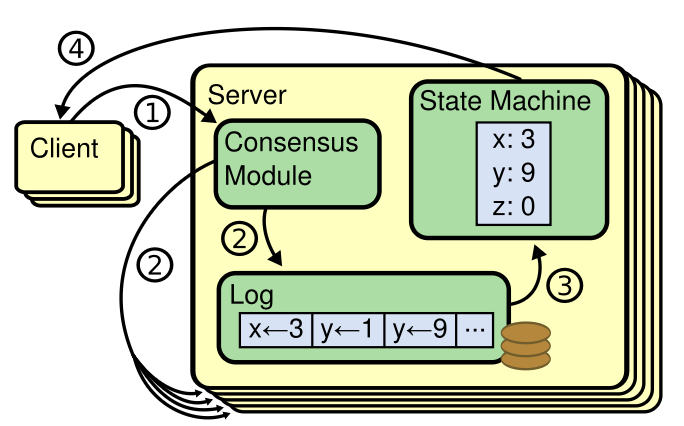
共识算法通常出现在复制状态机 [37] 的语境中。在该方法中,各服务器上的状态机计算相同状态的相同副本,即使部分服务器宕机也能继续运行。复制状态机用于解决分布式系统中的多种容错问题。例如,具有单一集群 leader 的大规模系统(如 GFS [8]、HDFS [38]、RAMCloud [33])通常使用独立的复制状态机来管理 leader 选举并存储必须在 leader 崩溃后保留的配置信息。复制状态机的例子包括 Chubby [2] 和 ZooKeeper [11]。
图 1: 复制状态机架构。共识算法管理一个包含来自客户端的 state machine 命令的复制日志。各 state machine 按相同顺序处理日志中的命令,因此产生相同输出。
复制状态机通常用复制日志实现,如图 1。每台服务器保存一个包含一系列命令的日志,由其 state machine 按序执行。每条日志包含相同命令且顺序相同,故每台 state machine 处理相同命令序列。由于 state machine 是确定性的,每台计算出相同状态与相同输出序列。